A*算法 - Something TO DO
A*算法
A*算法,寻找最优路径!
仍然是整理参考别人的总结,对应到代码详细的说明一下!
原文地址:http://www.policyalmanac.org/games/aStarTutorial.htm
中文网址http://zhyt710.iteye.com/blog/739803
假设有人想从A点移动到一墙之隔的B点,如下图,绿色的是起点A,红色是终点B,蓝色方块是中间的墙。
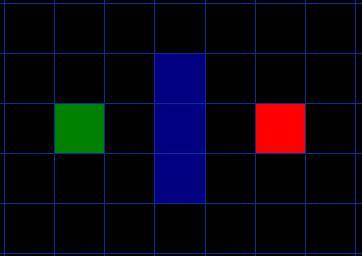
[图1]
定义一个node类来表示一个方块的所具有的属性(位置(xPos,yPos)+从起始点到当前点的距离(level)+优先级大小(priority=level+当前点到目标点距离估计)) F(priority)= G(level)+H(当前点到目标点距离估计)。
还有几个public属性的函数,包括更新优先级值大小的udatePriority函数,更新level值的nextLevel函数,估计距离目标值的estimate函数。
class node
{
private:
// current position
int xPos;
int yPos;
// total distance already travelled to reach the node
int level;
// priority=level+remaining distance estimate
int priority; // 值越小优先级越大
public:
node(int xp, int yp, int d, int p)
{xPos=xp; yPos=yp; level=d; priority=p;}
int getxPos() const {return xPos;}
int getyPos() const {return yPos;}
int getLevel() const {return level;}
int getPriority() const {return priority;}
void updatePriority(const int & xDest, const int & yDest)//更新当前点的优先级值
{
priority=level+estimate(xDest, yDest)*10; //A* F = G + H :G取值10或14 H取值为直线距离
}
// give better priority to going strait instead of diagonally
void nextLevel(const int & i) // i: direction 通过原node来计算其i方向的点的level
{
level+=(dir==8?(i%2==0?10:14):10);
}
// Estimation function for the remaining distance to the goal.
const int & estimate(const int & xDest, const int & yDest) const
{
static int xd, yd, d; //
xd=xDest-xPos;
yd=yDest-yPos;
// Euclidian Distance
d=static_cast<int>(sqrt(xd*xd+yd*yd));//static_cast<int>强制转换为整型
// Manhattan distance
//d=abs(xd)+abs(yd);
// Chebyshev distance
//d=max(abs(xd), abs(yd));
return(d);
}
};
你首先注意到,搜索区域被我们划分成了方形网格。像这样,简化搜索区域,是寻路的第一步。这一方法把搜索区域简化成了一个二维数组。数组的每一个元素是网格的一个方块,方块被标记为可通过的和不可通过的。路径被描述为从A到B我们经过的方块的集合。一旦路径被找到,我们的人就从一个方格的中心走向另一个,直到到达目的地。
static int dir_map[n][m]; // map of directions 是0-7的取值,表明当前节点的父节点
const int dir=8; // number of possible directions to go at any position
// 5|6|7
// 4| |0 ********
// 3|2|1
// if dir==4
//static int dx[dir]={1, 0, -1, 0};
//static int dy[dir]={0, 1, 0, -1};
// if dir==8
static int dx[dir]={1, 1, 0, -1, -1, -1, 0, 1};
static int dy[dir]={0, 1, 1, 1, 0, -1, -1, -1}; //
// -1| 0 | 1 -1| -1| -1
// -1| | 1 dx 0| | 0 dy 顺序与dir相同
// -1| 0 | 1 1| 1| 1
其中,每个节点可以向8(dir)个方向运动,8个方向从0-7表示,而且通过dir_map[n][m]表明他的父节点方向。通过dx[dir],dy[dir]来遍历一个节点的8个方向的节点(在后边的一段程序中比较直观)。
这些中点被称为“节点”。当你阅读其他的寻路资料时,你将经常会看到人们讨论节点。为什么不把他们描述为方格呢?因为有可能你的路径被分割成其他不是方格的结构。他们完全可以是矩形,六角形,或者其他任意形状。节点能够被放置在形状的任意位置-可以在中心,或者沿着边界,或其他什么地方。我们使用这种系统,无论如何,因为它是最简单的。
开始搜索
正如我们处理上图网格的方法,一旦搜索区域被转化为容易处理的节点,下一步就是去引导一次找到最短路径的搜索。在A*寻路算法中,我们通过从点A开始,检查相邻方格的方式,向外扩展直到找到目标。
我们做如下操作开始搜索:
1,从点A开始,并且把它作为待处理点存入一个“开启列表”。开启列表就像一张购物清单。尽管现在列表里只有一个元素,但以后就会多起来。你的路径可能会通过它包含的方格,也可能不会。基本上,这是一个待检查方格的列表。
2,寻找起点周围所有可到达或者可通过的方格,跳过有墙,水,或其他无法通过地形的方格。也把他们加入开启列表。为所有这些方格保存点A作为“父方格”。当我们想描述路径的时候,父方格的资料是十分重要的。后面会解释它的具体用途。
3,从开启列表中删除点A,把它加入到一个“关闭列表”,列表中保存所有不需要再次检查的方格。
static int map[n][m]; //地图表示形式 static int closed_nodes_map[n][m]; // map of closed (tried-out) nodes 关闭列表 static int open_nodes_map[n][m]; // map of open (not-yet-tried) nodes开启列表
在这一点,你应该形成如图的结构。在图中,暗绿色方格是你起始方格的中心。它被用浅蓝色描边,以表示它被加入到关闭列表中了。所有的相邻格现在都在开启列表中,它们被用浅绿色描边。每个方格都有一个灰色指针反指他们的父方格,也就是开始的方格。

图2
// 定义node类的priority_queue的数组pq[2],用两个vector的形式来统计开启列表和关闭列表
static priority_queue<node> pq[2]; // list of open (not-yet-tried) nodes // priority_queue 适配器
static int pqi; // pq index
static node* n0; //no为node类下的一个指针
static node* m0;
// create the start node and push into list of open nodes
n0=new node(xStart, yStart, 0, 0); //new动态内存管理,为node类分配了适当大小的内存
n0->updatePriority(xFinish, yFinish);//更新优先级大小
pq[pqi].push(*n0); // 把起始点压入vecotr中
open_nodes_map[xStart][yStart]=n0->getPriority(); // 将起始点的优先级的值赋给相应的开启列表中的值
// A* search
while(!pq[pqi].empty()) //插入起始点了,非空
{
// get the current node w/ the highest priority
// from the list of open nodes
n0=new node( pq[pqi].top().getxPos(), pq[pqi].top().getyPos(),
pq[pqi].top().getLevel(), pq[pqi].top().getPriority());
x=n0->getxPos(); y=n0->getyPos();
pq[pqi].pop(); // remove the node from the open list,将起始点从开启列表删除
open_nodes_map[x][y]=0;
// mark it on the closed nodes map 将起始点插入关闭列表
closed_nodes_map[x][y]=1;
// generate moves (child nodes) in all possible directions 考虑起始点8个方向的子节点
for(i=0;i<dir;i++)
{
xdx=x+dx[i]; ydy=y+dy[i];
if(!(xdx<0 || xdx>n-1 || ydy<0 || ydy>m-1 || map[xdx][ydy]==1
|| closed_nodes_map[xdx][ydy]==1)) //不超范围,不是障碍物,没有在关闭列表中所有节点
{
// generate a child node
m0=new node( xdx, ydy, n0->getLevel(),
n0->getPriority());
m0->nextLevel(i);
m0->updatePriority(xFinish, yFinish); //m0表示当前节点,更新level和priority
// if it is not in the open list then add into that
if(open_nodes_map[xdx][ydy]==0) //map of open (not-yet-tried) nodes
{
open_nodes_map[xdx][ydy]=m0->getPriority();
pq[pqi].push(*m0);
// mark its parent node direction
dir_map[xdx][ydy]=(i+dir/2)%dir;
}
else delete m0; // garbage collection为了释放空间,暂时不考虑
}
}
delete n0; // garbage collection 同为了释放空间
}
接着,我们选择开启列表中的临近方格,大致重复前面的过程,如下。但是,哪个方格是我们要选择的呢?是那个F值最低的。
路径评分
选择路径中经过哪个方格的关键是下面这个等式:
F = G + H
这里:
* G = 从起点A,沿着产生的路径,移动到网格上指定方格的移动耗费。
* H = 从网格上那个方格移动到终点B的预估移动耗费。这经常被称为启发式的,可能会让你有点迷惑。这样叫的原因是因为它只是个猜测。我们没办法事先知道路径的长度,因为路上可能存在各种障碍(墙,水,等等)。虽然本文只提供了一种计算H的方法,但是你可以在网上找到很多其他的方法。
我们的路径是通过反复遍历开启列表并且选择具有最低F值的方格来生成的。文章将对这个过程做更详细的描述。首先,我们更深入的看看如何计算这个方程。
正如上面所说,G表示沿路径从起点到当前点的移动耗费。在这个例子里,我们令水平或者垂直移动的耗费为10,对角线方向耗费为14。我们取这些值是因为沿对角线的距离是沿水平或垂直移动耗费的的根号2(别怕),或者约1.414倍。为了简化,我们用10和14近似。比例基本正确,同时我们避免了求根运算和小数。这不是只因为我们怕麻烦或者不喜欢数学。使用这样的整数对计算机来说也更快捷。你不就就会发现,如果你不使用这些简化方法,寻路会变得很慢。
既然我们在计算沿特定路径通往某个方格的G值,求值的方法就是取它父节点的G值,然后依照它相对父节点是对角线方向或者直角方向(非对角线),分别增加14和10。例子中这个方法的需求会变得更多,因为我们从起点方格以外获取了不止一个方格。
H值可以用不同的方法估算。我们这里使用的方法被称为曼哈顿方法,它计算从当前格到目的格之间水平和垂直的方格的数量总和,忽略对角线方向。然后把结果乘以10。这被成为曼哈顿方法是因为它看起来像计算城市中从一个地方到另外一个地方的街区数,在那里你不能沿对角线方向穿过街区。很重要的一点,我们忽略了一切障碍物。这是对剩余距离的一个估算,而非实际值,这也是这一方法被称为启发式的原因。想知道更多?你可以在这里找到方程和额外的注解。
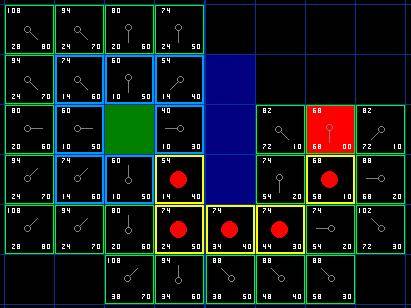
F的值是G和H的和。第一步搜索的结果可以在下面的图表中看到。F,G和H的评分被写在每个方格里。正如在紧挨起始格右侧的方格所表示的,F被打印在左上角,G在左下角,H则在右下角。
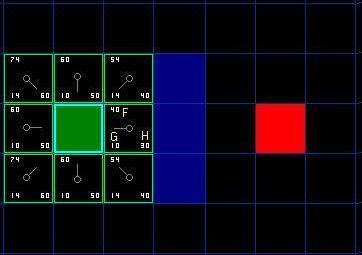
[图3]
现在我们来看看这些方格。写字母的方格里,G = 10。这是因为它只在水平方向偏离起始格一个格距。紧邻起始格的上方,下方和左边的方格的G值都等于10。对角线方向的G值是14。
H值通过求解到红色目标格的曼哈顿距离得到,其中只在水平和垂直方向移动,并且忽略中间的墙。用这种方法,起点右侧紧邻的方格离红色方格有3格距离,H值就是30。这块方格上方的方格有4格距离(记住,只能在水平和垂直方向移动),H值是40。你大致应该知道如何计算其他方格的H值了~。
每个格子的F值,还是简单的由G和H相加得到
继续搜索
为了继续搜索,我们简单的从开启列表中选择F值最低的方格。然后,对选中的方格做如下处理:
通过上边的一段程序中
if(open_nodes_map[xdx][ydy]==0) //map of open (not-yet-tried) nodes
{
open_nodes_map[xdx][ydy]=m0->getPriority();
pq[pqi].push(*m0);
// mark its parent node direction
dir_map[xdx][ydy]=(i+dir/2)%dir;
}
我们知道起始点周围的节点都不在开启类表中,然后经过上边这段程序把起始点周围8个节点全部加入开启列表,并且将父节点指向起始点。这时候前边的判断语句
while(!pq[pqi].empty())
又成立了(原来的pq的vector中只有起始点),接下来就是在所有的开启列表中通过下面一段程序选择F值最低的方格,选择F值最低的方法是通过重载operator<来比较使得pq[].top()得到的便是F值最低的
bool operator<(const node & a, const node & b)//通过重载operator<来重新对vector中的F值排序,使得F值最小的排在top()
{
return a.getPriority() > b.getPriority();
}
这样再从vector中取top()的节点就是在起始点的8个方向中F值最小的节点
n0=new node( pq[pqi].top().getxPos(), pq[pqi].top().getyPos(), pq[pqi].top().getLevel(), pq[pqi].top().getPriority());
4,把它从开启列表中删除,然后添加到关闭列表中。
5,检查所有相邻格子。跳过那些已经在关闭列表中的或者不可通过的(有墙,水的地形,或者其他无法通过的地形),把他们添加进开启列表,如果他们还不在里面的话。把选中的方格作为新的方格的父节点。
6,如果某个相邻格已经在开启列表里了,检查现在的这条路径是否更好。换句话说,检查如果我们用新的路径到达它的话,G值是否会更低一些。如果不是,那就什么都不做。
另一方面,如果新的G值更低,那就把相邻方格的父节点改为目前选中的方格(在上面的图表中,把箭头的方向改为指向这个方格)。最后,重新计算F和G的值。如果这看起来不够清晰,你可以看下面的图示。
好了,让我们看看它是怎么运作的。我们最初的9格方格中,在起点被切换到关闭列表中后,还剩8格留在开启列表中。这里面,F值最低的那个是起始格右侧紧邻的格子,它的F值是40。因此我们选择这一格作为下一个要处理的方格。在紧随的图中,它被用蓝色突出显示。
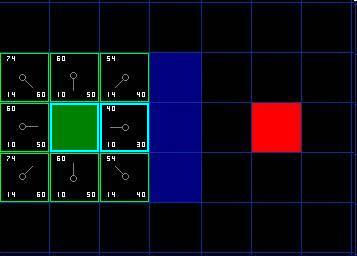
[图4]
首先,我们把它从开启列表中取出,放入关闭列表(这就是他被蓝色突出显示的原因)。然后进行的操作和对于起始点是一样的,然后我们检查相邻的格子。哦,右侧的格子是墙,所以我们略过。左侧的格子是起始格。它在关闭列表里,所以我们也跳过它。
其他4格已经在开启列表里了,于是我们检查G值来判定,如果通过这一格到达那里,路径是否更好。我们来看选中格子下面的方格。它的G值是14。如果我们从当前格移动到那里,G值就会等于20(到达当前格的G值是10,移动到上面的格子将使得G值增加10)。因为G值20大于14,所以这不是更好的路径。如果你看图,就能理解。与其通过先水平移动一格,再垂直移动一格,还不如直接沿对角线方向移动一格来得简单。
当我们对已经存在于开启列表中的4个临近格重复这一过程的时候,我们发现没有一条路径可以通过使用当前格子得到改善,所以我们不做任何改变。既然我们已经检查过了所有邻近格,那么就可以移动到下一格了。
于是我们检索开启列表,现在里面只有7格了,我们仍然选择其中F值最低的。有趣的是,这次,有两个格子的数值都是54。我们如何选择?这并不麻烦。从速度上考虑,选择最后添加进列表的格子会更快捷。这种导致了寻路过程中,在靠近目标的时候,优先使用新找到的格子的偏好。但这无关紧要。(对相同数值的不同对待,导致不同版本的A*算法找到等长的不同路径。)
那我们就选择起始格右下方的格子,如图。
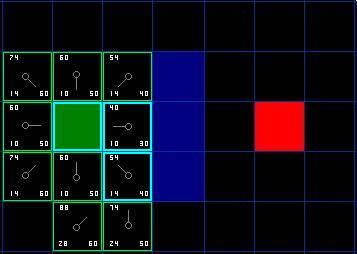
[图5]
这次,当我们检查相邻格的时候,发现右侧是墙,于是略过。上面一格也被略过。我们也略过了墙下面的格子。为什么呢?因为你不能在不穿越墙角的情况下直接到达那个格子。你的确需要先往下走然后到达那一格,按部就班的走过那个拐角。(注解:穿越拐角的规则是可选的。它取决于你的节点是如何放置的。)
这样一来,就剩下了其他5格。当前格下面的另外两个格子目前不在开启列表中,于是我们添加他们,并且把当前格指定为他们的父节点。其余3格,两个已经在关闭列表中(起始格,和当前格上方的格子,在表格中蓝色高亮显示),于是我们略过它们。最后一格,在当前格的左侧,将被检查通过这条路径,G值是否更低。不必担心,我们已经准备好检查开启列表中的下一格了。
我们重复这个过程,直到目标格被添加进关闭 列表(注解) ,就如在下面的图中所看到的。

[图6]
注意,起始格下方格子的父节点已经和前面不同的。之前它的G值是28,并且指向右上方的格子。现在它的G值是20,指向它上方的格子。这在寻路过程中的某处发生,当应用新路径时,G值经过检查变得低了-于是父节点被重新指定,G和F值被重新计算。尽管这一变化在这个例子中并不重要,在很多场合,这种变化会导致寻路结果的巨大变化。它对应的代码如下所示:
else if(open_nodes_map[xdx][ydy]>m0->getPriority())
{
// update the priority info
open_nodes_map[xdx][ydy]=m0->getPriority();
// update the parent direction info
dir_map[xdx][ydy]=(i+dir/2)%dir;
// replace the node
// by emptying one pq to the other one
// except the node to be replaced will be ignored
// and the new node will be pushed in instead
while(!(pq[pqi].top().getxPos()==xdx &&
pq[pqi].top().getyPos()==ydy))
{
pq[1-pqi].push(pq[pqi].top());
pq[pqi].pop();
}
pq[pqi].pop(); // remove the wanted node
// 把size小的pq转移到size大的pq中,并压入新的数据*m0
if(pq[pqi].size()>pq[1-pqi].size()) pqi=1-pqi;
while(!pq[pqi].empty())
{
pq[1-pqi].push(pq[pqi].top());
pq[pqi].pop();
}
pqi=1-pqi;
pq[pqi].push(*m0); // add the better node instead
}
那么,我们怎么确定这条路径呢?很简单,从红色的目标格开始,按箭头的方向朝父节点移动。这最终会引导你回到起始格,这就是你的路径!看起来应该像图中那样。从起始格A移动到目标格B只是简单的从每个格子(节点)的中点沿路径移动到下一个,直到你到达目标点。就这么简单。对应的代码:
if(x==xFinish && y==yFinish)
{
// generate the path from finish to start
// by following the directions
string path="";
while(!(x==xStart && y==yStart))
{
j=dir_map[x][y]; //取值范围0-7
c='0'+(j+dir/2)%dir;
path=c+path; //字符串形式输出路径,数字表示方向如(********)所示
x+=dx[j];
y+=dy[j];
}
// garbage collection
delete n0;
// empty the leftover nodes
while(!pq[pqi].empty()) pq[pqi].pop();
return path;
}
[图7]
A*方法总结
好,现在你已经看完了整个说明,让我们把每一步的操作写在一起:
1,把起始格添加到开启列表。
2,重复如下的工作:
a) 寻找开启列表中F值最低的格子。我们称它为当前格。
b) 把它切换到关闭列表。
c) 对相邻的8格中的每一个?
* 如果它不可通过或者已经在关闭列表中,略过它。反之如下。
* 如果它不在开启列表中,把它添加进去。把当前格作为这一格的父节点。记录这一格的F,G,和H值。
* 如果它已经在开启列表中,用G值为参考检查新的路径是否更好。更低的G值意味着更好的路径。如果是这样,就把这一格的父节点改成当前格,并且重新计算这一格的G和F值。如果你保持你的开启列表按F值排序,改变之后你可能需要重新对开启列表排序。
d) 停止,当你
* 把目标格添加进了关闭 列表( 注解 ), 这时候路径被找到,或者
* 没有找到目标格,开启列表已经空了。这时候,路径不存在。
3.保存路径。从目标格开始,沿着每一格的父节点移动直到回到起始格。这就是你的路径。
最后给出完整的代码:
// Astar.cpp
// http://en.wikipedia.org/wiki/A*
// Compiler: Dev-C++ 4.9.9.2
// FB - 201012256
#include <iostream>
//#include <fstream> //输出到文档需要添加的头文件
#include <iomanip>
#include <queue>
#include <string>
#include <math.h>
#include <ctime>
using namespace std;
const int n=60; // horizontal size of the map
const int m=60; // vertical size size of the map
static int map[n][m];
static int closed_nodes_map[n][m]; // map of closed (tried-out) nodes
static int open_nodes_map[n][m]; // map of open (not-yet-tried) nodes
static int dir_map[n][m]; // map of directions 取值是什么形式? 应该是0-7的取值吧
const int dir=8; // number of possible directions to go at any position
// 5|6|7
// 4| |0 ********
// 3|2|1
// if dir==4
//static int dx[dir]={1, 0, -1, 0};
//static int dy[dir]={0, 1, 0, -1};
// if dir==8
static int dx[dir]={1, 1, 0, -1, -1, -1, 0, 1};
static int dy[dir]={0, 1, 1, 1, 0, -1, -1, -1}; //
// -1| 0 | 1 -1| -1| -1
// -1| | 1 dx 0| | 0 dy 顺序与dir相同
// -1| 0 | 1 1| 1| 1
class node
{
private:
// current position
int xPos;
int yPos;
// total distance already travelled to reach the node
int level;
// priority=level+remaining distance estimate
int priority; // smaller: higher priority
public:
node(int xp, int yp, int d, int p)
{xPos=xp; yPos=yp; level=d; priority=p;}
int getxPos() const {return xPos;}
int getyPos() const {return yPos;}
int getLevel() const {return level;}
int getPriority() const {return priority;}
void updatePriority(const int & xDest, const int & yDest)//按引用传递参数,并且限定为const,使得xDest,yDest不能被修改
{
priority=level+estimate(xDest, yDest)*10; //A* F = G + H :G取值10或14 H取值为直线距离
}
// give better priority to going strait instead of diagonally
void nextLevel(const int & i) // i: direction 通过原node来计算其i方向的点的level
{
level+=(dir==8?(i%2==0?10:14):10);
}
// Estimation function for the remaining distance to the goal.
const int & estimate(const int & xDest, const int & yDest) const
{
static int xd, yd, d; //
xd=xDest-xPos;
yd=yDest-yPos;
// Euclidian Distance
d=static_cast<int>(sqrt(xd*xd+yd*yd));//static_cast<int>强制转换为整型
// Manhattan distance
//d=abs(xd)+abs(yd);
// Chebyshev distance
//d=max(abs(xd), abs(yd));
return(d);
}
};
//优先级队列顾名思义是根据元素的优先级被读取,
//接口和queues非常相近。程序员可以通过template参数指定一个排序准则。
//缺省的排序准则是利用operator< 形成降序排列,那么所谓“下一个元素”就是“数值最大的元素”。
// Determine priority (in the priority queue) 压栈的是指向node开始位的指针 ,然后 priority queue中
bool operator<(const node & a, const node & b)//通过重载operator<来比较自己定义的node类中优先级的大小
{
return a.getPriority() > b.getPriority();
}
// A-star algorithm.
// The route returned is a string of direction digits.
string pathFind( const int & xStart, const int & yStart,
const int & xFinish, const int & yFinish )
{
static priority_queue<node> pq[2]; // list of open (not-yet-tried) nodes // priority_queue 适配器
static int pqi; // pq index
static node* n0; //no为node类下的一个指针
static node* m0;
static int i, j, x, y, xdx, ydy;
static char c;
pqi=0;
// reset the node maps
for(y=0;y<m;y++)
{
for(x=0;x<n;x++)
{
closed_nodes_map[x][y]=0;
open_nodes_map[x][y]=0;
}
}
// create the start node and push into list of open nodes
n0=new node(xStart, yStart, 0, 0); //new动态内存管理,为node类分配了适当大小的内存
n0->updatePriority(xFinish, yFinish);//更新优先级大小
pq[pqi].push(*n0);
open_nodes_map[xStart][yStart]=n0->getPriority(); // mark it on the open nodes map (not-yet-tried)
// A* search
while(!pq[pqi].empty())
{
// get the current node w/ the highest priority
// from the list of open nodes
n0=new node( pq[pqi].top().getxPos(), pq[pqi].top().getyPos(),
pq[pqi].top().getLevel(), pq[pqi].top().getPriority());
x=n0->getxPos(); y=n0->getyPos();
pq[pqi].pop(); // remove the node from the open list
open_nodes_map[x][y]=0;
// mark it on the closed nodes map
closed_nodes_map[x][y]=1;
// quit searching when the goal state is reached
//if((*n0).estimate(xFinish, yFinish) == 0)
if(x==xFinish && y==yFinish)
{
// generate the path from finish to start
// by following the directions
string path="";
while(!(x==xStart && y==yStart))
{
j=dir_map[x][y]; //取值范围0-7
c='0'+(j+dir/2)%dir;
path=c+path; //字符串形式输出路径,数字表示方向如(********)所示
x+=dx[j];
y+=dy[j];
}
// garbage collection
delete n0;
// empty the leftover nodes
while(!pq[pqi].empty()) pq[pqi].pop();
return path;
}
// generate moves (child nodes) in all possible directions
for(i=0;i<dir;i++)
{
xdx=x+dx[i]; ydy=y+dy[i];
if(!(xdx<0 || xdx>n-1 || ydy<0 || ydy>m-1 || map[xdx][ydy]==1
|| closed_nodes_map[xdx][ydy]==1)) //不超范围,不是障碍物,没有在关闭列表中所有节点
{
// generate a child node
m0=new node( xdx, ydy, n0->getLevel(),
n0->getPriority());
m0->nextLevel(i);
m0->updatePriority(xFinish, yFinish);
// if it is not in the open list then add into that
if(open_nodes_map[xdx][ydy]==0) //map of open (not-yet-tried) nodes
{
open_nodes_map[xdx][ydy]=m0->getPriority();
pq[pqi].push(*m0);
// mark its parent node direction
dir_map[xdx][ydy]=(i+dir/2)%dir;
}
//已经在open list中的node:xdx,ydy,如果他们以当前点计算得到的优先级较高(数值小),
//那么就覆盖之前的优先级数值,并且改变他们的父节点
else if(open_nodes_map[xdx][ydy]>m0->getPriority())
{
// update the priority info
open_nodes_map[xdx][ydy]=m0->getPriority();
// update the parent direction info
dir_map[xdx][ydy]=(i+dir/2)%dir;
// replace the node
// by emptying one pq to the other one
// except the node to be replaced will be ignored
// and the new node will be pushed in instead
while(!(pq[pqi].top().getxPos()==xdx &&
pq[pqi].top().getyPos()==ydy))
{
pq[1-pqi].push(pq[pqi].top());
pq[pqi].pop();
}
pq[pqi].pop(); // remove the wanted node
// 把size小的pq转移到size大的pq中,并压入新的数据*m0
if(pq[pqi].size()>pq[1-pqi].size()) pqi=1-pqi;
while(!pq[pqi].empty())
{
pq[1-pqi].push(pq[pqi].top());
pq[pqi].pop();
}
pqi=1-pqi;
pq[pqi].push(*m0); // add the better node instead
}
else delete m0; // garbage collection
}
}
delete n0; // garbage collection
}
return ""; // no route found
}
int main()
{
srand(time(NULL));
// create empty map
for(int y=0;y<m;y++)
{
for(int x=0;x<n;x++) map[x][y]=0;
}
// fillout the map matrix with a '+' pattern as the obstacles
for(int x=n/8;x<n*7/8;x++)
{
map[x][m/2]=1;
}
for(int y=m/8;y<m*7/8;y++)
{
map[n/2][y]=1;
}
// randomly select start and finish locations
int xA, yA, xB, yB;
switch(rand()%8)
{
case 0: xA=0;yA=0;xB=n-1;yB=m-1; break;
case 1: xA=0;yA=m-1;xB=n-1;yB=0; break;
case 2: xA=n/2-1;yA=m/2-1;xB=n/2+1;yB=m/2+1; break;
case 3: xA=n/2-1;yA=m/2+1;xB=n/2+1;yB=m/2-1; break;
case 4: xA=n/2-1;yA=0;xB=n/2+1;yB=m-1; break;
case 5: xA=n/2+1;yA=m-1;xB=n/2-1;yB=0; break;
case 6: xA=0;yA=m/2-1;xB=n-1;yB=m/2+1; break;
case 7: xA=n-1;yA=m/2+1;xB=0;yB=m/2-1; break;
}
cout<<"Map Size (X,Y): "<<n<<","<<m<<endl;
cout<<"Start: "<<xA<<","<<yA<<endl;
cout<<"Finish: "<<xB<<","<<yB<<endl;
// get the route
clock_t start = clock();
string route=pathFind(xA, yA, xB, yB);
if(route=="") cout<<"An empty route generated!"<<endl;
clock_t end = clock();
double time_elapsed = double(end - start);
cout<<"Time to calculate the route (ms): "<<time_elapsed<<endl;
cout<<"Route:"<<endl;
cout<<route<<endl<<endl;
// follow the route on the map and display it
if(route.length()>0)
{
int j; char c;
int x=xA;
int y=yA;
map[x][y]=2;
for(int i=0;i<route.length();i++)
{
c =route.at(i);
j=atoi(&c); //int atoi(const char *nptr);字符串转换成整型数的一个函数
x=x+dx[j];
y=y+dy[j];
map[x][y]=3;
}
map[x][y]=4;
// display the map with the route
for(int y=0;y<m;y++)
{
for(int x=0;x<n;x++)
if(map[x][y]==0)
cout<<".";
else if(map[x][y]==1)
cout<<"O"; //obstacle
else if(map[x][y]==2)
cout<<"S"; //start
else if(map[x][y]==3)
cout<<"R"; //route
else if(map[x][y]==4)
cout<<"F"; //finish
cout<<endl;
}
}
//输出到txt文档
/* ofstream outFile;
outFile.open("map.txt");
for(int i = 0;i<n;i++)
{
for(int j=0;j<m;j++)
{
outFile<<map[i][j];
}
outFile<<'\n';
}
outFile.close();
*/
getchar(); // wait for a (Enter) keypress
return(0);
}
2022年8月25日 15:50
You may quickly check the PNR live status of your rail ticket. All you need to do to check the status of an Indian Railways PNR is input your PNR number and click the button. Your live PNR status will be shown in a new window that will open. pnr status with name The ability to check IRCTC PNR status online by entering the passenger's name or not is a common point of misunderstanding among users. You cannot check the IRCTC PNR status with a name, though, as each passenger's personal information is kept private.
2023年7月27日 18:12
Arunachal Pradesh SCERT 2nd Textbook 2024 are Prepared by Senior Experts and is the best resource used by Primary Students to prepare for Half Year and Final Exam 2024. Arunachal Pradesh Textbook 2024 are Created for the Students to get an idea about the Subject. So Arunachal Pradesh. primary Students can get a best Foundation in the Subject with the help of These textbooks.State Council SCERT Itanagar 2nd Class Book 2024 of Educational Research and Training Arunachal Pradesh Itanagar Every Year Publish and Distortion in Class Textbooks and Study Materiel, Arunachal Pradesh Books 2024 as well as Useful to form Little Primary School Students.